Nov 08 2022
Turn a Terraform Map of Maps into a Single Map…
…Or how to avoid the ‘Call to function “merge” failed: arguments must be maps or objects, got “tuple”.’ error message. Maps of maps example.

Issue Producing a Single Map
Here’s a typical 2 level data structure that fits users in subgroups, themselves belonging to departments:
locals {
groups = {
it = {
admin = ["it1","it2"]
editors = ["it3","it4"]
},
accounts = {
editors = ["account1","account2"]
viewers = ["account3","account4"]
}
}
}
There are good chances you will need to flatten that structure to create some Terraform ressources.
Our target is a map of unique subgroups department_subgroup = [ “user1”, “user2” ]. In our example:
subgroups = {
"accounts_editors" = [
"account1",
"account2",
]
"accounts_viewers" = [
"account3",
"account4",
]
"it_admin" = [
"it1",
"it2",
]
"it_editors" = [
"it3",
"it4",
]
}
It is pretty simple to get a list of distinct maps flattening the resulting lists of a double loop:
subgroups = flatten([
for group,subgroups in local.groups : [
for subgroup, users in subgroups : {
"${group}_${subgroup}" = users
}
]
])
# output:
subgroups = [
{
"accounts_editors" = [
"account1",
"account2",
]
},
{
"accounts_viewers" = [
"account3",
"account4",
]
},
{
"it_admin" = [
"it1",
"it2",
]
},
{
"it_editors" = [
"it3",
"it4",
]
},
]All we need is merge these maps into a single map but if we do, we end up with:
‘Call to function “merge” failed: arguments must be maps or objects, got “tuple”.’
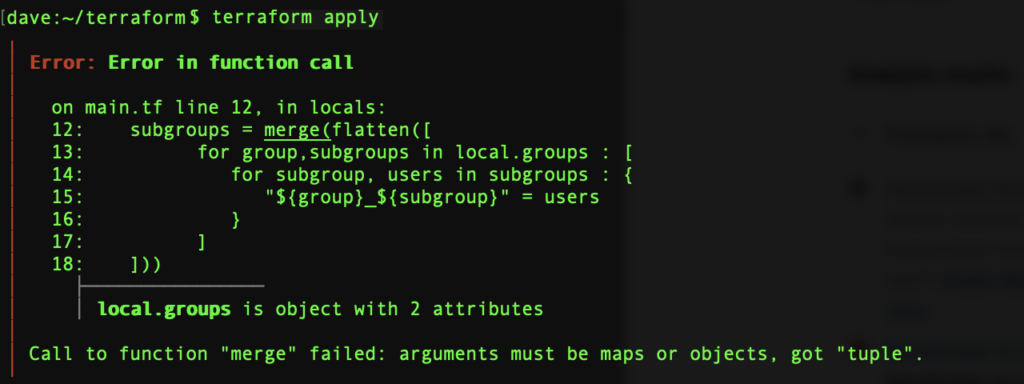
2 ways to the rescue: the ugly and the elegant.
The Ugly Way : Another Terraform Loop
The first way you can think of is to process the new map through another for loop. That makes 3 loops and does not make any sense since a simple merge would do the job. Each map has one element only, so we take the first key and first value.
subgroups = { for subgroup in flatten([
for group,subgroups in local.groups : [
for subgroup, users in subgroups : {
"${group}_${subgroup}" = users
}
]
]) : keys(subgroup)[0] => values(subgroup)[0] }
The Elegant Way : Function Expansion
This is much shorter than above solution:
subgroups = merge(flatten([
for group,subgroups in local.groups : [
for subgroup, users in subgroups : {
"${group}_${subgroup}" = users
}
]
])...)The result is exactly the same but what has changed? Just the 3 dots…
Expansion takes each element out of a list and pass them on to the calling function.

