Déc 30 2007
Heartbeat 2: Mise en oeuvre
Note importante:
Heartbeat est maintenant obsolète et a migré vers une nouvelle stack disponible sur Clusterlabs. Pour un projet de haute disponibilité simple utilisant une IP virtuelle, essayez keepalived qui fait la surveillance et la bascule juste avec un simple fichier de configuration.
Depuis sa version 2, Heartbeat est capable de gérer plus de 2 noeuds, et surtout n’a plus besoin de l’utilitaire « mon » pour la surveillance des services. Cette fonctionnalité est directement intégrée. Par conséquent, la hausse du nombre de possibilités a complexifié la configuration de Heartbeat. Il est à noter que les fichiers version 1 sont toujours suportés.
Installation
Les sources de Heartbeat sont disponibles sur le site officiel http://www.linux-ha.org. Des rpms compatibles Redhat Enterprise sont téléchargeables depuis le site de Centos (lien inclus sur le site Heartbeat). Les packages sont mis à jour relativement vite puisque la version source est la 2.1.0 alors que le rpm est la 2.0.8-2 lors de cette installation. 3 rpms sont nécessaires:
heartbeat-pils
heartbeat-stonith
heartbeat
Le service monitoré sera Apache mais la configuration reste valide pour n’importe quel autre service: mail, bases de données, DNS, DHCP, serveurs de fichiers, etc…
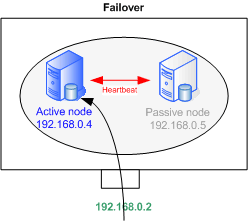
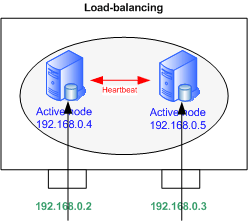
Schéma
Failover ou load-balancing
Heartbeat supporte les modèles Actif-Passif pour le failover et Actif-Actif pour le load-balancing. De nombreuses autres configurations sont possibles en ajoutant des serveurs et/ou services; Les possibilités sont énormes.
Nous traiterons du load-balancing ici, seules quelques lignes devront être supprimées pour le failover.
 |
 |
Configuration
Dans cette configuration, les 2 serveurs sont interconnectés via leur interface eth0. Les flux applicatifs arrivent sur eth1, laquelle est configuée comme dans le schéma ci-dessus, avec les adresses 192.168.0.4 et .5 Les adresses sur eth0 doivent appartenir à un sous-réseau dédié à Heartbeat. Ces adresses doivent apparaître dans /etc/hosts sur chaque noeud.
3 fichiers sont nécessaires à la configuration de Heartbeat 2. Ils doivent être identiques sur tous les noeuds.
Sous /etc/ha.d/
– ha.cf
– authkeys
Sous /var/lib/heartbeat/crm/
– cib.xml
ha.cf
ha.cf contient les paramètres généraux tels que les noeuds du cluster ou la topologie des communications.
use_logd on # Fréquence d'envoi des paquets Heartbeat keepalive 500ms # secondes - Spécifier ms pour des temps inférieur à 1 seconde # Laps de temps après lequel un noeud est considéré "mort" deadtime 2 # Envoi d'un message warning # Important pour ajuster la valeur deadtime warntime 1 # Identique à deadtime mais lors de l'initialisation initdead 8 updport 694 # Test du host pour vérifier que le host est toujours en ligne # La passerelle par défaut en général ping 192.168.0.1 # Interface sur laquelle les "Heartbeats" sont envoyés # Utiliser "serial" pour un port série, # "mcast" et "ucast" respectivement pour multicast et unicast bcast eth0 # La resource bascule sur le noeud primaire dès qu'il redevient disponible auto_failback on # Liste des noeuds faisant partie du cluster node n1.domain.com node n2.domain.com # Activer la config Heartbeat 2 crm yes # Permet d'ajouter un nouveau en live sans reconfigurer les anciens noeuds autojoin any
D’autres options sont disponibles telles que la compression ou le débit pour la communication sur cable série. Consulter http://linux-ha.org/ha.cf
authkeys
Authkeys permet de définir les clés d’authentification. Plusieurs types sont disponibles: crc, md5 et sha1. crc est à utiliser sur un réseau qui est déjà sécurisé (vlan isolé ou cable croisé. sha1 offre un niveau de sécurité haute mais consomme beaucoup de ressource processeur. md5 est un intermédiaire tout-à-fait satisfaisant.
auth 1 1 md5 secret
Le mot de passe est stocké en clair, il est important de changer les permissions du fichier avec un chmod 600.
cib.xml
<cib>
<configuration>
<crm_config/>
<nodes/>
<resources>
<group id="server1">
<primitive class="ocf" id="IP1" provider="heartbeat" type="IPaddr">
<operations>
<op id="IP1_mon" interval="10s" name="monitor" timeout="5s"/>
</operations>
<instance_attributes id="IP1_inst_attr">
<attributes>
<nvpair id="IP1_attr_0" name="ip" value="192.168.0.2"/>
<nvpair id="IP1_attr_1" name="netmask" value="24"/>
<nvpair id="IP1_attr_2" name="nic" value="eth1"/>
</attributes>
</instance_attributes>
</primitive>
<primitive class="lsb" id="apache1" provider="heartbeat" type="apache">
<operations>
<op id="apache1_mon" interval="30s" name="monitor" timeout="20s"/>
</operations>
</primitive>
</group>
<group id="server2">
<primitive class="ocf" id="IP2" provider="heartbeat" type="IPaddr">
<operations>
<op id="IP2_mon" interval="10s" name="monitor" timeout="5s"/>
</operations>
<instance_attributes id="IP2_inst_attr">
<attributes>
<nvpair id="IP2_attr_0" name="ip" value="192.168.0.3"/>
<nvpair id="IP2_attr_1" name="netmask" value="24"/>
<nvpair id="IP2_attr_2" name="nic" value="eth1"/>
</attributes>
</instance_attributes>
</primitive>
<primitive class="lsb" id="apache2" provider="heartbeat" type="apache">
<operations>
<op id="apache2_mon" interval="30s" name="monitor" timeout="20s"/>
</operations>
</primitive>
</group>
</resources>
<constraints>
<rsc_location id="location_server1" rsc="server1">
<rule id="best_location_server1" score="100">
<expression_attribute="#uname" id="best_location_server1_expr" operation="eq" value="n1.domain.com"/>
</rule>
</rsc_location>
<rsc_location id="location_server2" rsc="server2">
<rule id="best_location_server2" score="100">
<expression_attribute="#uname" id="best_location_server2_expr" operation="eq" value="n2.domain.com"/>
</rule>
</rsc_location>
<rsc_location id="server1_connected" rsc="server1">
<rule id="server1_connected_rule" score="-INFINITY" boolean_op="or">
<expression id="server1_connected_undefined" attribute="pingd" operation="not_defined"/>
<expression id="server1_connected_zero" attribute="pingd" operation="lte" value="0"/>
</rule>
</rsc_location>
<rsc_location id="server2_connected" rsc="server2">
<rule id="server2_connected_rule" score="-INFINITY" boolean_op="or">
<expression id="server2_connected_undefined" attribute="pingd" operation="not_defined"/>
<expression id="server2_connected_zero" attribute="pingd" operation="lte" value="0"/>
</rule>
</rsc_location>
</constraints>
</configuration>
</cib>
Il est possible de générer ce fichier depuis le fichier de configuration Heartbeat1, haresources situé dans /etc/ha.d/, gràce à la commande suivante:
python /usr/lib/heartbeat/haresources2cib.py > /var/lib/heartbeat/crm/cib.xml
De manière globale, le fichier se décompose en 2 parties: les ressources et les contraintes.
Ressources
Les ressources sont organisées sous forme de groupes (server1 & 2) rassemblant une adresse IP virtuelle et un service: Apache. Les ressources sont déclarées avec la syntaxe <primitive> à l’intérieur du groupe. Les groupes sont utiles pour rassembler plusieurs ressources répondant aux mêmes contraintes.
La primitive IP1 surveille que l’adresse virtuelle 1 est bien joignable. Elle fait appel au script IPaddr de type OCF. Les scripts OCF sont fournis avec Heartbeat et se situent dans l’arborescence des rpms. Il est possible de spécifier l’adresse virtuelle, son masque de réseau ainsi que l’interface qui va l’accueillir.
La ressource apache est de type LSB, c’est-à-dire qu’elle fait appel à un script de démarrage situé dans /etc/init.d. Le nom du script est entré dans la variable type: type= »nom ». Pour fonctionner avec Heartbeat, le script doit respecter la norme LSB. La norme LSB spécifie entre autres que l’on doit pouvoir:
- collecter le status du service par « script status »
- exécuter un « script start » sur un service déjà démarré
- arréter un service déjà arrété
Toutes les spécifications LSB sont disponibles à l’adresse http://www.linux- ha.org/LSBResourceAgent
Les temps définissables ici sont:
- interval: temps avant qu’une action ne soit considérée en échec et redémarrée
- timeout: définit le temps avant qu’une action du type start, stop ou status ne soit considérée en échec
Contraintes
2 contraintes sont appliquées à chaque groupe de ressources:
La location préférée oû les ressources « devraient » s’exécuter. On donne un score de 100 à n1.domain.com pour le 1er groupe de ressources. Ainsi, si n1.domain.com est actif, et que l’option auto_failback est à « on », les ressources du 1er groupe reviendront toujours sur cette machine.
L’action suivant le ping. Si aucun des gateways ne répond aux pings, les ressources sont migrées vers un autre serveur, et le noeud est mis en standby.
Le score -INFINITY signifie qu’en aucun cas, la machine ne doit accepter les ressources si les gateways sont injoignables.
Notes importantes
Droits sur les fichiers
Le répertoire /etc/ha.cf contient des données sensibles. Il est obligatoire de changer les droits en lecture/écriture pour le propriétaire – ou l’application ne se lancera pas.
chmod 600 /etc/ha.d/ha.cf
Le fichier /var/lib/heartbeat/crm/cib.crm doit appartenir à hacluster et au groupe haclient. Il ne doit pas être accessible aux autres utilisateurs.
chown hacluster:haclient /var/lib/heartbeat/crm/cib.crm
chmod 660 /var/lib/heartbeat/crm/cib.crm
Le fichier cib.xml est accédé en écriture par l’application Heartbeat. Des fichiers sont créés en parallèle. Si une édition manuelle est nécessaire, arréter Heartbeat sur tous les noeuds, effacer cib.xml.sig dans le même répertoire, éditer cib.xml sur tous les noeuds, et redémarrer Heartbeat.
Il faut normalement utiliser la commande crm_resource pour réaliser ces modifications (voir section plus bas).
Interfaces
Les interfaces où vont résider les adresses virtuelles n’ont pas besoin d’être configurées ni d’avoir une une adresse physique, théoriquement. Cela permettait de réduire le nombre d’adresses à utiliser. L’interface doit toutefois être activée lors du démarrage (Un simple DEVICE=eth1 dans /etc/sysconfig/network-scripts/ifcfg-eth1 suffit). Les adresses virtuelles sont toujours créées en tant que sous-interfaces, ex: eth0:0, même dans le cas ou l’interface principale n’est pas configurée.
Fichier hosts
Le fichier /etc/hosts doit obligatoirement contenir les noms de tous les noeuds faisant partie du cluster. Ces noms doivent être identiques à la commande ‘uname -n’.
Démarrage des services
Heartbeat se charge du démarrage d’Apache lorsque celui-ci est inactif. Il est préférable de désactiver Apache avec chkconfig par exemple, celui-ci pouvant mettre un certain temps à se lancer, Heartbeat pourrait essayer de démarrer le service une deuxième fois.
chkconfig httpd off
Un script de démarrage est présent dans /etc/init.d/. Pour lancer Heartbeat, exécuter « /etc/init.d/hearbeat start ». Il est préférable que Heartbeat se lance automatiquement:
chkconfig heartbeat on
Comportement et tests
Les actions suivantes permettent de simuler des incidents qui pourraient avoir lieu au quotidien, et altérer le bon fonctionnement du cluster. Le comportement de Heartbeat a été étudié dans chaque cas.
Arrêt d’Apache
Le service Heartbeat local va redémarrer Apache. Si le redémarrage échoue, un warning sera ajouté dans les logs. Heartbeat n’essayera plus de lancer le service. L’adresse IP virtuelle reste sur la machine et n’est pas migrée. Cela dit, l’adresse peut être migrée manuellement avec les outils Heartbeat.
Arrêt ou crash d’un serveur
Les adresses virtuelles migrent vers les autres serveurs.
Arrêt manuel de Heartbeat sur un noeud
Apache est arrêté par Heartbeat. Les adresses virtuelles de la machine sont migrées vers les autres serveurs. La procédure normale serait d’utiliser la commande crm_standby pour mettre la machine en standby et migrer les ressources.
Déconnexion du cable entre les 2 serveurs
Chaque machine se croit « seule » et s’approprie les 2 adresses virtuelles. Toutefois, cela ne semblent pas poser de problème puisque le gateway continue d’envoyer les paquets à l’adresse ARP présente dans sa table. Un ping sur l’adresse de broadcast renvoie des duplicats.
Déconnexion de la passerelle
Ceci pourrait survenir dans 2 situations:
– Le gateway est indisponible. Dans ce cas, les 2 noeuds vont supprimer leur adresse IP virtuelle et arréter Apache.
– La connexion de l’un des noeuds au réseau est tombée. Les adresses sont migrées vers l’autre serveur qui a normalement encore accès à la passerelle.
Tous les cas envisagés permettent de maintenir le système en vie sauf dans le cas où la passerelle est tombée. Ceci n’est plus du ressort du cluster…
Outils
Plusieurs outils sont disponibles pour vérifier le comportement de Heartbeat.
Logs
Heartbeat utilise le démon logd qui envoie les logs dans le fichier système /var/log/messages.
Outils Unix
Les commandes Unix usuelles peuvent être employées. Heartbeat crée des sous-interfaces que l’on peut visualiser avec « ifconfig » ou « ip address show ». L’état des processus sont visualisables avec les scripts de démarrage ou encore la commande « ps ».
Commandes Heartbeat
Heartbeat offre une série de commandes fournies dans le package rpm. Voici les principales:
- crmadmin: Permet de gérer les managers de noeuds sur chaque machine du cluster.
- crm_mon: Pratique et rapide; Permet de visualiser l’état des noeuds et ressources.
- crm_resource: Fait des requêtes et modifie les données relatives aux ressources/services. Possibilité de lister, migrer, désactiver et supprimer des ressources.
- crm_verify: Reporte les warnings et erreurs sur le cluster
- crm_standby: Migre toutes les ressources d’un noeud. Utile lors des mises à jour par exemple.
Maintenance
Arrêt du service
Lors d’une mise à jour ou d’un arrêt d’Apache, procéder comme ceci:
- Arrêter Apache sur le noeud 1 et migrer l’adresse virtuelle sur le noeud 2:
crm_standby -U n1.domain.com -v true - Effectuer les mises à jour sur n1 puis redémarrer le noeud:
crm_standby -U n1.domain.com -v false - Les ressources reviennent automatiquement sur n1 (si cib.xml a bien été configuré)
Effectuer la même démarche sur n2
Rem: La mise en standby de n2 peut être faite depuis n1 et vice versa.
Il est possible de mettre les 2 noeuds en standby en même temps; Apache sera arrété sur les 2 machines et les adresses virtuelles supprimées jusqu’à ce que l’on sorte du mode standby.
Reboot de la machine
Il n’est pas nécessaire de mettre le noeud en standby avant un reboot. Néanmoins, cela est préférable puisque le temps de migration des ressources sera plus court, si l’on considère le temps passé à détecter que le noeud n’est plus disponible.
Remise en service d’une ressource
Exemple: Apache a planté et ne redémarre plus, toutes les ressources du groupe sont migrées vers le deuxième serveur.
Lorsque le problème est résolu et que la ressource est à nouveau disponible, revérifier l’ensemble des ressources par la commande:
crm_resource –reprobe (-P)
et réinitialiser la ressource:
crm_resource –cleanup –resource apache1 (ou crm_resource -C -r apache1).
Elle sera automatiquement migré vers son serveur d’origine.
Ajout d’une nouvelle machine dans le cluster
En backup
Si le cluster est composé de 2 noeuds connectés par un cable croisé, il faudra désormais un switch pour les interfaces où les « Heartbeats » sont envoyés.
Il faut tout d’abord ajouter les nouvelles informations relatives au nouveau noeud. Editer le fichier /etc/hosts des noeuds existants et y ajouter le hostname du nouveau noeud. Le contenu doit être copié sur la nouveau serveur. Configurer Heartbeat de la même manière que sur les autres noeuds.
Les fichiers ha.cf doivent contenir l’instruction « autojoin any » pour accepter l’ajout d’un nouveau noeud.
Sur la nouvelle machine, démarrer Heartbeat; La machine devrait joindre le cluster automatiquement.
Si ce n’est pas le cas, exécuter la commande suivante sur l’un des noeuds faisant déjà partie du cluster:
/usr/lib/heartbeat/hb_addnode n3.domain.com
Le nouveau noeud ne fait qu’office de backup, aucun service n’y sera associé. Si n1.domain.com passe en mode standby, ses ressources basculerons sur n3. Elles reviendront sur le serveur d’origine dès que celui-ci sera disponible (la préférence étant fixée pour ce serveur).
Avec un nouveau service
Pour ajouter une 3me IP (associée à un troisième Apache), il faut exécuter la procédure ci-dessus puis:
– Soit stopper Heartbeat sur les 3 serveurs et éditer les fichiers cib.xml
– Soit construire des fichiers similaires à cib.xml, ne contenant que les ressources et contraintes à ajouter, puis les insérer sur le cluster à chaud. Ceci est méthode préférée. Créer les 3 fichiers suivants sur l’un des noeuds:
newGroup.xml
<group id="server3">
<primitive class="ocf" provider="heartbeat" type="IPaddr" id="IP3">
<operations>
<op id="IP3_mon" interval="5s" name="monitor" timeout="2s"/>
</operations>
<instance_attributes id="IP3_attr">
<attributes>
<nvpair id="IP3_attr_0" name="ip" value="192.168.0.28"/>
<nvpair id="IP3_attr_1" name="netmask" value="29"/>
<nvpair id="IP3_attr_2" name="nic" value="eth1"/>
</attributes>
</instance_attributes>
</primitive>
<primitive class="lsb" provider="heartbeat" type="apache" id="apache3">
<operations>
<op id="apache3_mon" interval="5s" name="monitor" timeout="5s"/>
</operations>
</primitive>
</group>
newLocationConstraint.xml
<rsc_location id="location_server3" rsc="server3">
<rule id="best_location_server3" score="100">
<expression attribute="#uname" id="best_location_server3_expr" operation="eq" value="n3.domain.com"/>
</rule>
</rsc_location>
newPingConstraint.xml
<rsc_location id="server3_connected" rsc="server3">
<rule id="server3_connected_rule" score="-INFINITY" boolean_op="or">
<expression id="server3_connected_undefined" attribute="pingd" operation="not_defined"/>
<expression id="server3_connected_zero" attribute="pingd" operation="lte" value="0"/>
</rule>
</rsc_location>
Ajouter les contraintes de server3
cibadmin -C -o constraints -x newLocationConstraint.xml
cibadmin -C -o constraints -x newPingConstraint.xml
Ajouter les ressources de server3
cibadmin -C -o resources -x newGroup.xml
Les ressources relatives à server3 devraient démarrer automatiquement.
Note: Les ajouts se font un par un. Si 2 contraintes sont entrées dans le même fichier, seule la 1re sera prise en compte.
je vous félicite super tuto il ma beaucoup aider !!!!
merci a vous .
Très bien foutu ce tuto, j’ai hâte de pouvoir l’essayer :)
Attention erreur pour le ha.cf :
s/updport/udpport/
Bonjour,
Tout d’abord merci pour ce tutorial très intéressant.
J’aurais une question concernant la surveillance du serveur Apache. Vous dites que si le service Apache s’arrête l’adresse IP virtuelle reste sur la machine et n’est pas migrée. N’est-il pas possible de migrer automatiquement la ressource adresse IP et apache sur l’autre serveur.
C’est le comportement que j’ai noté. J’ai été assez étonné aussi.
Peut-etre qu’il est possible d’ajouter une condition ou un nombre maximal de tentatives apres laquelle l’IP migre.
Si quelqu’un a une solution…
crm_attribute –attr-name default-resource-failure-stickiness –attr-value 1
pour forcer la bascule d\’un service.
Pourquoi dire que vous allez traiter du mode load-balancing, alors qu\’en faite vous décrivez le mode failover ?
Et sinon quand on est en heartbeatv2 on peut utiliser hb_guy, pour ajouter/modifier des service \"à chaud\".
Bonjour,
Le load-balancing peut être réalisé en ajoutant une 2me IP virtuelle (voir plus) avec une préférence pour le 2me serveur. Si l’un des serveurs devenait indisponible, les 2 IPs virtuelles se retrouveraient sur un seul et même serveur de cette facon (avec une seule IP). Il s’agit donc d’un simple ajout de config.
L’interface graphique Heartbeat n’est pas réputée stable et ne permet d’accéder qu’aux fonctions les plus basiques si ma mémoire est bonne.
Bonjour et merci pour ce très bon tuto.
J\’utilise heartbeat (version 2 crm) pour un cluster de base de données MySQL. Je suis en train de modifier mon architecture pour intégrer un lien physique entre les serveurs pour la prise de pouls. J\’ai donc :
S1
eth0 -> lien physique
eth1 -> lien sur le réseau
S2
eth0 -> lien physique
eth1 -> lien sur le réseau
Vous l\’avez compris, mes interfaces eth0 sont connectés ensembles et heartbeat tourne dessus. La prise de pouls se fait donc par eth0 et la VIP est montée sur eth1
J\’ai configuré tout ça avec hb_gui permettant de générer le cib.xml
J\’ai 2 problèmes :
1 – Je voudrai que heartbeat puisse détecter l\’état de mon lien eth1 et donc faire basculer la VIP sur l\’autre serveur (à l\’heure actuelle, si je fais tomber le lien d\’eth1 avec un ifdown, rien ne se passe).
2 – Je voudrai empêcher la VIP de revenir sur S1 lorsqu\’il revient sur le réseau. Pour celà, j\’ai mis mon auto_failback à off, mais ça n\’a pas l\’air de fonctionner. J\’imagine que je dois configurer autre chose en plus pour le faire fonctionner.
Que signifie le score sur les noeuds ?
Je n\’arrive pas à comprendre le fonctionnement avec 2 cartes réseau. une pour la negoce entre les deux noeuds et l\’autre pour l\’exploitation des PC clients. J\’espère que vous pourrez m\’aider.
1 – Heartbeat vérifie eth1 en faisant un ping sur la passerelle, c’est normalement défini dans ha.cf (ping ip_passerelle)
2 – Je n’ai plus ma config de test mais il me semble que si le score est plus haut sur le 1er serveur, l’IP rebasculera toujours. Peut-être en mettant des scores identiques?
Les score ne sont qu’une valeur pondérale pour définir des préférences. 100 ou 1000, peu importe et -INFINY et INFINY pour ne jamais ou toujours basculer.
Bonjour,
J’aurais souhaité savoir s’il était possible d’éviter d’avoir un lien physique dédié pour le test du battement de coeur heartbeat.
En effet, on est censé attribuer deux ip d’un sous réseau privé dédié, mais peut-on mettre deux ip PUBLIC toujours d’un même sous-réseau? heartbeat le supporte t’il? Arrive t’il a pinger le nœud esclave et master entre eux?
Merci pour votre réponse.
Cordialement.
Bonjour,
Il me semble l’avoir déjà réalisé lors de tests, mais je ne vois pas l’intérêt!?
Les IPs de prod peuvent être publiques et le lien Heartbeat en IPs privées.
Le système sera moins robuste et plus difficile à gérer car en cas de perte de l’un des liens, les 2 machines ne pourront plus dialoguer.
» C’est le comportement que j’ai noté. J’ai été assez étonné aussi.
Peut-etre qu’il est possible d’ajouter une condition ou un nombre maximal de tentatives apres laquelle l’IP migre.
Si quelqu’un a une solution… »
Par la définition des méta attributs pour le group
l’@IP et le serveur apache sont situés sur la même machine (colocated )
et ordonné (ordered) l’@IP doit monter avant la ressource apache
…
De cette façon si apache tombe il démarre sur l’autre machine l’@IP et ensuite le serveur apache…