Mai 16 2021
MySQL / PostgreSQL sur Disques iSCSI ne Démarre pas au Boot
Vous hébergez les répertoires de données Mysql ou PostgreSQL sur des disques iSCSI mais le service ne démarre pas au boot du serveur. Le service ne trouve pas le répertoire. Pourtant, le service se lance manuellement après s’être loggué en SSH dès qu’il est disponible.

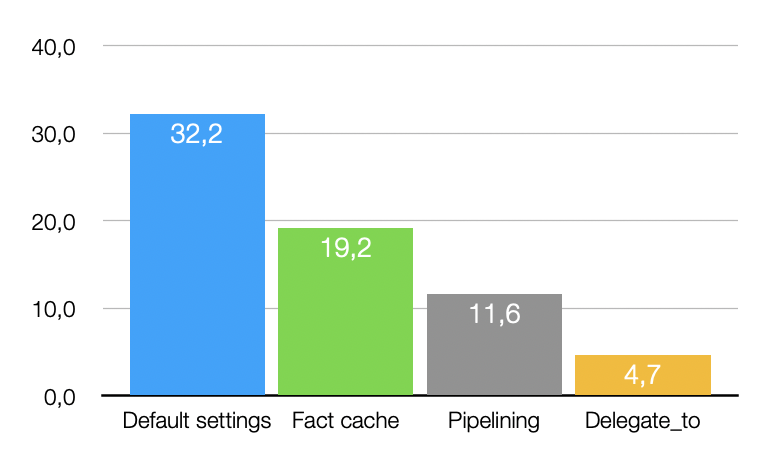
Voici les logs de Mariadb mais ils seraient similaires pour Mysql:
mariadbd[795]: 0 [Note] /usr/sbin/mysqld (mysqld 10.5.9-MariaDB-1:10.5.9+maria~buster-log) starting as process 795 ...
mariadbd[795]: 0 [Warning] Can't create test file /opt/db/data/database_server.lower-test
mariadbd[795]: #007/usr/sbin/mysqld: Cannot change dir to '/var/lib/mysql/data/' (Errcode: 2 "No such file or directory")
mariadbd[795]: 0 [ERROR] Aborting
systemd[1]: mariadb.service: Main process exited, code=exited, status=1/FAILURE
systemd[1]: mariadb.service: Failed with result 'exit-code'.
systemd[1]: Failed to start MariaDB 10.5.9 database server.
Vous auriez des logs similaires pour PostgreSQL. J’ai stocké les données PostgreSQL sur une partition XFS, elle-même rrésidant sur LVM pour une gestion de l’espace disque plus flexible, comme l’ajout d’espace pendant que le système de fichiers est monté. C’est probablement la raison principale qui fait que les disques iSCSI sont populaires.
systemd: mounting /var/lib/pgsql
starting PostgreSQL database server
sd 2:0:0:0: [sdb] attached SCSI disk
xfs (dm-4): Mounting V4 Filesystem
postgresql-check-db-dir: "/var/lib/pgsql/data" is missing or empty
postgresql.service: control process exited, code=exited status=1
Failed to start PostgreSQL database server.
La base de données qui démarre manuellement après le boot indique certainement un problème d’ordre de démarrage des services. Les bases de données doivent démarrer après que les disques iscsi sont disponibles. Cela peut être résolu en ajoutant « After=remote-fs.target » dans le fichier systemd du service comme /usr/lib/systemd/system/postgresql-9.5.service pour PosgreSQL par exemple. C’est un moyen de gérer la précédence et les dépendances des services.
Notez que vous pourriez perdre ces changement la prochaine fois que le paquet est mis à jour. Systemd permet de créer un fichier supplémentaire où vous pouvez définir vos propres paramètres. Il ne sera jamais écrasé puisque c’est votre fichier, indépendant du paquet.
Créez simplement /etc/systemd/system/mariadb.service.d/override.conf comme ceci pour Mariadb, c’est la même procédure pour Mysql ou PostgreSQL:
[Service]
Environment="UMASK_DIR=0750"
[Unit]
After=remote-fs.target
Dans ce fichier, j’ai aussi changé les droits par défaut du répertoire de données pour que les utilisateurs appartenant au groupe Mysql puissent le parcourir.
Exécutez systemctl daemon-reload pour que les nouveaux changements soient pris en compte et redémarrez le serveur. La base de données devrait maintenant démarrer.