Nov 13 2022
Convertir une Map de Maps en Map Unique
..Ou comment éviter le message d’erreur ‘Call to function « merge » failed: arguments must be maps or objects, got « tuple ».’. L’exemple avec une map de maps.

Problème à la Création d’une Map
Voici une structure de données typique à 2 niveaux avec des sous-groupes qui contiennent des utilisateurs, eux-mêmes appartenant à des départements:
locals {
groups = {
it = {
admin = ["it1","it2"]
editors = ["it3","it4"]
},
accounts = {
editors = ["account1","account2"]
viewers = ["account3","account4"]
}
}
}
La structure devra être nivelée (flatten) dans de nombreux cas pour créer des resources Terraform.
Notre cible est une map de sous-groupes uniques departement_sous-group = [ « user1 », « user2 » ]. Dans notre exemple:
subgroups = {
"accounts_editors" = [
"account1",
"account2",
]
"accounts_viewers" = [
"account3",
"account4",
]
"it_admin" = [
"it1",
"it2",
]
"it_editors" = [
"it3",
"it4",
]
}
C’est assez simple d’obtenir une liste de maps distinctes en nivelant les listes résultantes d’une double boucle:
subgroups = flatten([
for group,subgroups in local.groups : [
for subgroup, users in subgroups : {
"${group}_${subgroup}" = users
}
]
])
# output:
subgroups = [
{
"accounts_editors" = [
"account1",
"account2",
]
},
{
"accounts_viewers" = [
"account3",
"account4",
]
},
{
"it_admin" = [
"it1",
"it2",
]
},
{
"it_editors" = [
"it3",
"it4",
]
},
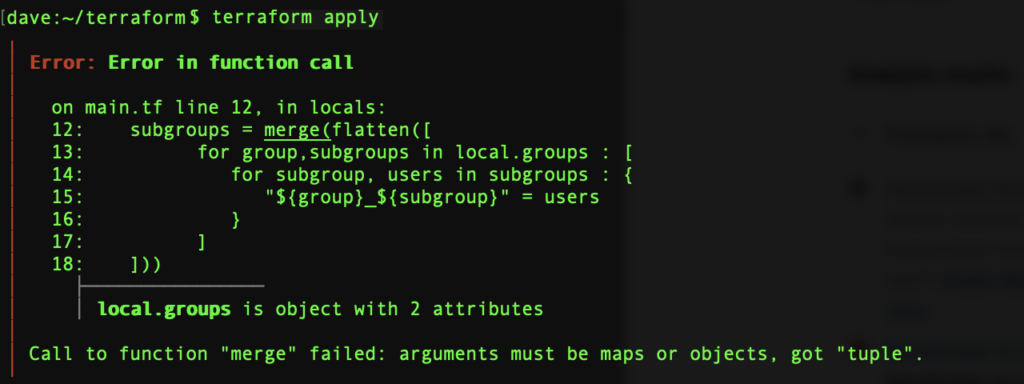
]Tout ce qu’il nous reste à faire est de fusionner ces maps en une map unique, mais ce faisant, le message d’erreur nous est retourné:
‘Call to function « merge » failed: arguments must be maps or objects, got « tuple ».’
2 recours possibles: le moche et l’élégant.
La Solution Moche : Une Autre Boucle Terraform
La 1re solution qui vient à l’esprit est de générer la nouvelle map via une autre boucle for. Cela nous amène à 3 boucles, et ne semble pas très logique alors qu’un simple merge ferait le travail. Chaque map contient un élément seulement, donc nous prenons les 1res clé et valeur.
subgroups = { for subgroup in flatten([
for group,subgroups in local.groups : [
for subgroup, users in subgroups : {
"${group}_${subgroup}" = users
}
]
]) : keys(subgroup)[0] => values(subgroup)[0] }
La Solution Elégante : la Fonction Expansion
C’est beaucoup plus court que la solution précédente:
subgroups = merge(flatten([
for group,subgroups in local.groups : [
for subgroup, users in subgroups : {
"${group}_${subgroup}" = users
}
]
])...)Le résultat est exactement le même mais qu’est-ce qui a changé? Juste les 3 points…
La fonction Expansion prend chaque élément d’une liste et led passe à la fonction appelante.

